Почему именно я говорю про эффективность?
1. Это моя работа. И я добиваюсь в ней результата.
С 2012 я Head of PM (product & project management), Head of Delivery. Эта работа предполагает "сделать так, чтобы внутри оно работало".
От момента создания продуктовых гипотез и/или постановки целей или ориентиров на год/квартал - чтобы все это было подхвачено, правильно оценено и обсуждено, ничего по дороге не потеряно, выявлены риски и зависимости. И главное, чтобы без лишней волокиты и без авралов сделано, с вовлечением заинтересованных сторон, с максимальной ценностью для пользователя.
От момента создания продуктовых гипотез и/или постановки целей или ориентиров на год/квартал - чтобы все это было подхвачено, правильно оценено и обсуждено, ничего по дороге не потеряно, выявлены риски и зависимости. И главное, чтобы без лишней волокиты и без авралов сделано, с вовлечением заинтересованных сторон, с максимальной ценностью для пользователя.
2. У меня есть насмотренность.
В крупных продуктовых компаниях (СберЕаптека, 3Commas, N3), в классическом проектном управлении, в реальном производстве (выпуск софта для томографов и самих томографов), и даже в цирке. :)
Ниже попытаюсь объяснить, к каким общим принципам управления эффективностью пришел за время проектной и продуктовой карьеры.
Что такое эффективность?
"Работать эффективно" - не значит "вкалывать в режиме героизма" или "с максимально возможной скоростью". В современном ИТ есть такая тенденция - ускорять доставку ценности, проверку гипотез, настраивать производственные процессы. И все это действительно важно, если мы не сваливаемся в фанатизм. Ведь эффективно, не значит "быстрее всех".
Эффективная команда - та что работает стабильно (это важно) и предсказуемо (тоже важно) достигает поставленных целей без "надрыва", без чрезмерных рисков и без неоправданных потерь.
Измерение эффективности немыслимо без оценки:
- добиваемся ли целей и с какой скоростью (скорость важна, да),
- предсказуема ли наша работа (мы сами знаем "когда закончим" и можем ли сориентировать других),
- хорошо ли людям в нашей команде (климат, ощущения, текучка)
- что окружающие, в первую очередь пользователи, работодатели и заказчики думают о нас.
Когда измеряю эффективность, я пытаюсь оцифровать эти показатели. Так появляются метрики.
Хорошо разработанные метрики страхуют меня и все мои команды от когнитивных искажений, неоправданного субъективизма - негатива или эйфории. Помогают искать зоны роста. И к тому же чрезвычайно упрощают коммуникацию, в том числе с топ-менеджментом.
На метрики можно полагаться, принимая решения об организационных изменениях (какой эффект мы хотим увидеть через 2-4-20 недель и в каком случае мы остановим и "откатим" то, что запланировали сделать). Я бы даже сказал иначе - не стоит проводить организационные изменения никак иначе.
Как же разработать подходящие метрики?
А что - бывают метрики, которые подходят всем?
Я не буду пытаться объять необъятное и предложить "серебряную пулю". Поделюсь лишь своими соображениями какие цифры полезно анализировать в любой компании или команде которые делают что либо полезное для пользователя
Умышленно разберу все только на примере Канбан метода. Это самый наглядный и удобный подход для сбора метрик (к слову, использовал его во всех продуктовых компаниях на Portfolio-уровне). Также, настаиваю: при определенной смекалке вы можете собрать независимо от управленческого подхода (говорю это как сертифицированный не только KMP, но и PMP специалист) :)
В качестве примера мы будем ориентироваться на продуктовую компанию (на самом деле для компаний, ориентированных на проекты, измерять эффективность намного проще и статья вышла бы очень банальной, так что поставим себе планку по-выше).
Итак: продуктовая компания, предположим что используется лишь канбан метод.
Итак: продуктовая компания, предположим что используется лишь канбан метод.
Главные группы метрик
Выделю три основные группы:
- Метрики работы
- Метрики бизнеса и продукта
- Метрики комфорта
Метрики работы - это, грубо говоря "как перформим". Главная трудность тут сопоставлять "сравнимое со сравнимым". Если это удастся, то cможем делать выводы типа "сколько у нас уходило на задачу такой-то трудоемкости в прошлом году и какой она стала сейчас", сможем изучить что этому помогло.. На этих метриках остановимся подробно.
Метрики бизнеса и продукта - это главные "бизнесовые" показатели для компании. От них зависит "в плюсе ли мы", "нравимся ли инвесторам", "сойдется ли юнит экономика". Менеджер проектов обязан вовлекаться в отслеживание этих метрик, но роль "первой скрипки" тут все же за руководителями продуктов и высшим руководством которые этот самый бизнес основали или им руководят. Так что этим метрикам уделим пару слов.
Метрики комфорта - отражают самочувствие людей. В ИТ-компаниях люди и их отношение к вам, к работе, к другим коллегам имеют большое значение. Невозможно пытаться "повысить эффективность", не делая повседневную работу для коллег лучше и удобнее. Тем более опасно увеличивать уровень дискомфорта там, где вся работа делается "головой". Потому, это вспомогательная группа метрик, но и серьезные выводы без нее невозможны. Если зажглась "красная лампочка" дискомфорта - по-возможности, пытаемся справиться с этой проблемой, прежде чем снова прокачивать "рабочие" и "продуктовые" аспекты.
Возражение
Возражение: "Фигня какая-то! Почему не смотреть только на деньги? Компания либо прибыльна, либо нет. Вот и вся эффективность. Это бизнес, видите ли. Нерентабельные тут не выживают. И все что вы там наколдуете на уровне команд, никакого значения не имеет. Важно лишь зарабатываем мы или нет. Так что EBITDA да NPV - вот наши метрики. Остальное дело десятое.
Ответ: Потому, что это мало что вам расскажет об эффективности. Но давайте поясню.
Во-первых, нерентабельные иногда выживают довольно долго. А во-вторых прибыль - это не самый чувствительный, иногда очень "запаздывающий" показатель. Я повидал достаточное количество и государственных и частных компаний (оседлавших определенную нишу или группу заказчиков) - чудовищно неэффективных и невероятно богатых. Иногда дело было банально в коррупции (тут не о чем говорить, воровство меня не интересует даже в части анализа). Но часто - дело просто в стечении обстоятельств, в удаче.
Кого-то забросило наверх, потому что ключевой клиент, с которым работали годами резко стал монополистом, Кто-то поднялся вместе с рынком (таковы 99% криптостарmапов пару лет назад, или стартапы, связанные с AI/ML/DS прямо сейчас, или, как во времена моей молодости медицинский ИТ рынок во время своего роста). Бывают этапы, когда любой стартап в индустрии поднимает сумасшедшие раунды под невнятные обещания.
Словом, "прилив поднимает все лодки".
Кто-то становится богатым, благодаря эффективности, а кто-то вопреки. Если на вашей улице перевернулся подобный "грузовик с пряниками" в ответ на ваш крайне сырой MVP - это усыпляет бдительность. Собственно, пряники очень часто оказываются "конечны", а быстро перепрофилироваться или побороться за взыскательного клиента на падающем рынке может только эффективная компания.
Так что, не дайте большим деньгам и хорошим финансовым показателям (если они у вас есть) - себя убаюкать. Если нет, то тем более внимательно читаем дальше :)
Группа I. Метрики работы
Метрики работы - отражают как наша идея превращается в результат.
Включают: показатели скорости (TTM, CT), показатели простоев (FE), нашу способность реалистично планировать (отклонения от вех), пропускную способность (throughput), и россыпь маленьких метрик, которыми мы точечно обкладываем потенциальные болевые точки в командах или всей компании
Time to Market (TTM)
Time to market, TTM - сколько времени прошло от момента, когда клиент "попросил", до момента, когда он это "получил" (смогу использовать).
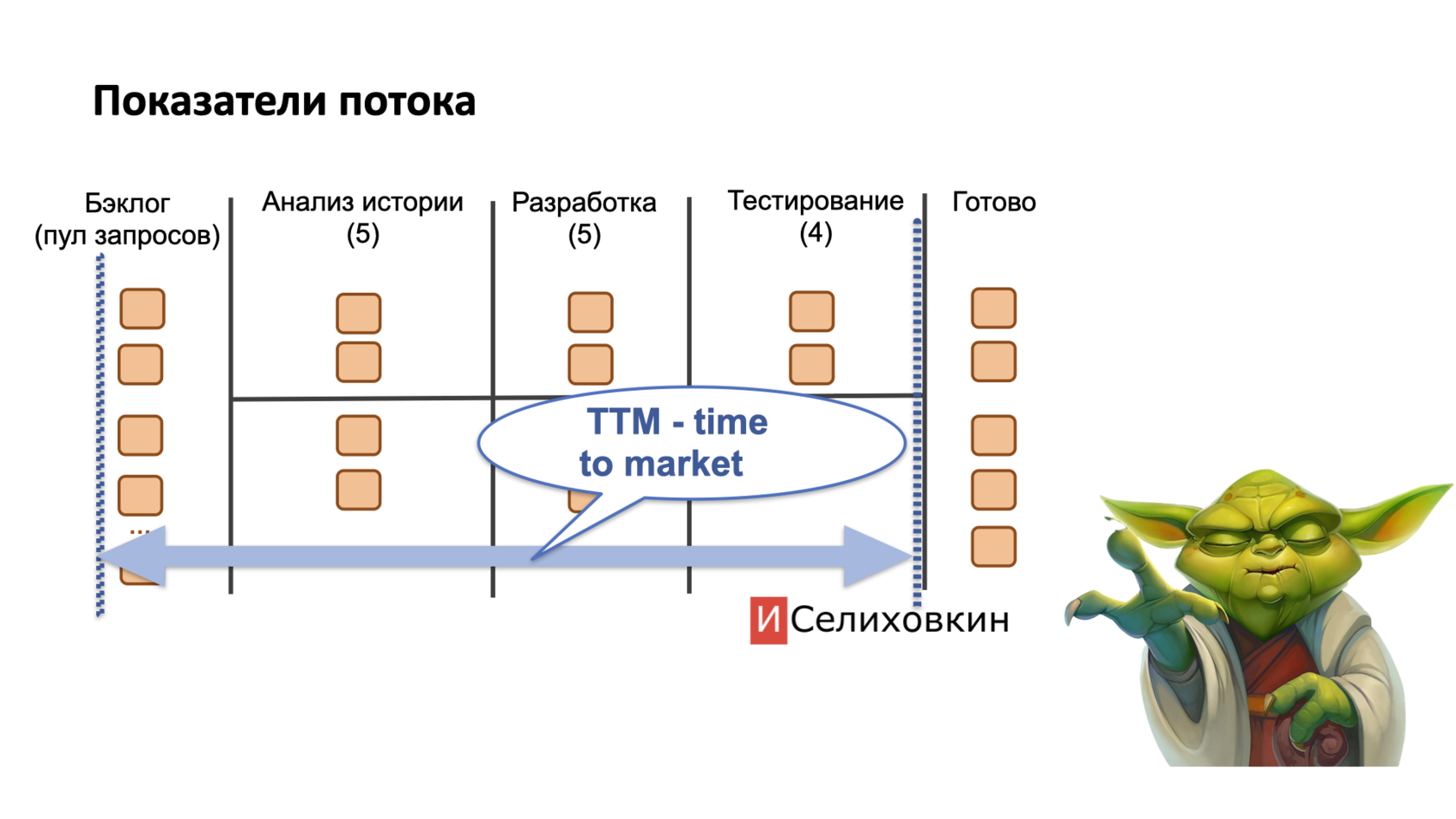
Чтобы померить TTM, нужно засечь время, когда мы "положили" запрос в бэклог. Подчеркну - не завели карточку в условную Jira, а именно полностью и внятно сформулировали "что хотим" и теперь ожидаем, чтобы кто-то "следующий" взял наш запрос в работу.
Также нужно зафиксировать момент, когда запрос переведен в "финальный статус" (что-то типа Done). Также подчеркну - не "сделан разработчиками", а полностью доступен пользователю без всяких оговорок (протестирован, опубликован, прошел апрув платформы [иногда актуально для приставок и мобильных приложений] и готов к использованию).
Большинство современных таск-треккеров и систем для управления умеют это делать автоматически. Некоторые в состоянии автоматически вычислить разницу - т.е. полностью посчитать TTM для вас. Например, та же Jira может отображать его на дашбордах или в отчетах.
Смысл метрики - понять "сколько ждет клиент" (будь то продакт-овнер, лид сторонней команды попросивший у нас выкатить фичу или пользователь, который столкнулся с проблемой и сообщил о ней в техподдержку).
Чем больше TTM, тем дольше ждет пользователь. Тем, предположительно, грустнее он становится.
Но TTM не говорит о производительности команды. Для этого нужен другой показатель - CT.
Смысл метрики - понять "сколько ждет клиент" (будь то продакт-овнер, лид сторонней команды попросивший у нас выкатить фичу или пользователь, который столкнулся с проблемой и сообщил о ней в техподдержку).
Чем больше TTM, тем дольше ждет пользователь. Тем, предположительно, грустнее он становится.
Но TTM не говорит о производительности команды. Для этого нужен другой показатель - CT.
Cycle Time (CT)
Cycle Time, CT - сколько времени прошло от момента когда команда взялась за реализацию запроса (т.е. с той секунды когда кто-то вытащил его из бэклога) до момента, когда запрос был реализован и официально получил финальный статус ("Done").
У термина Cycle Time есть синонимы (некоторые коллеги пользуются другим названием - Lead Time, а сам термин Cycle Time применяют иначе - будьте внимательны, уточняйте на всякий случай у собеседника что он имеет ввиду)
Cycle Time отражает скорость работы команды. Чем он короче, тем команда шустрее.
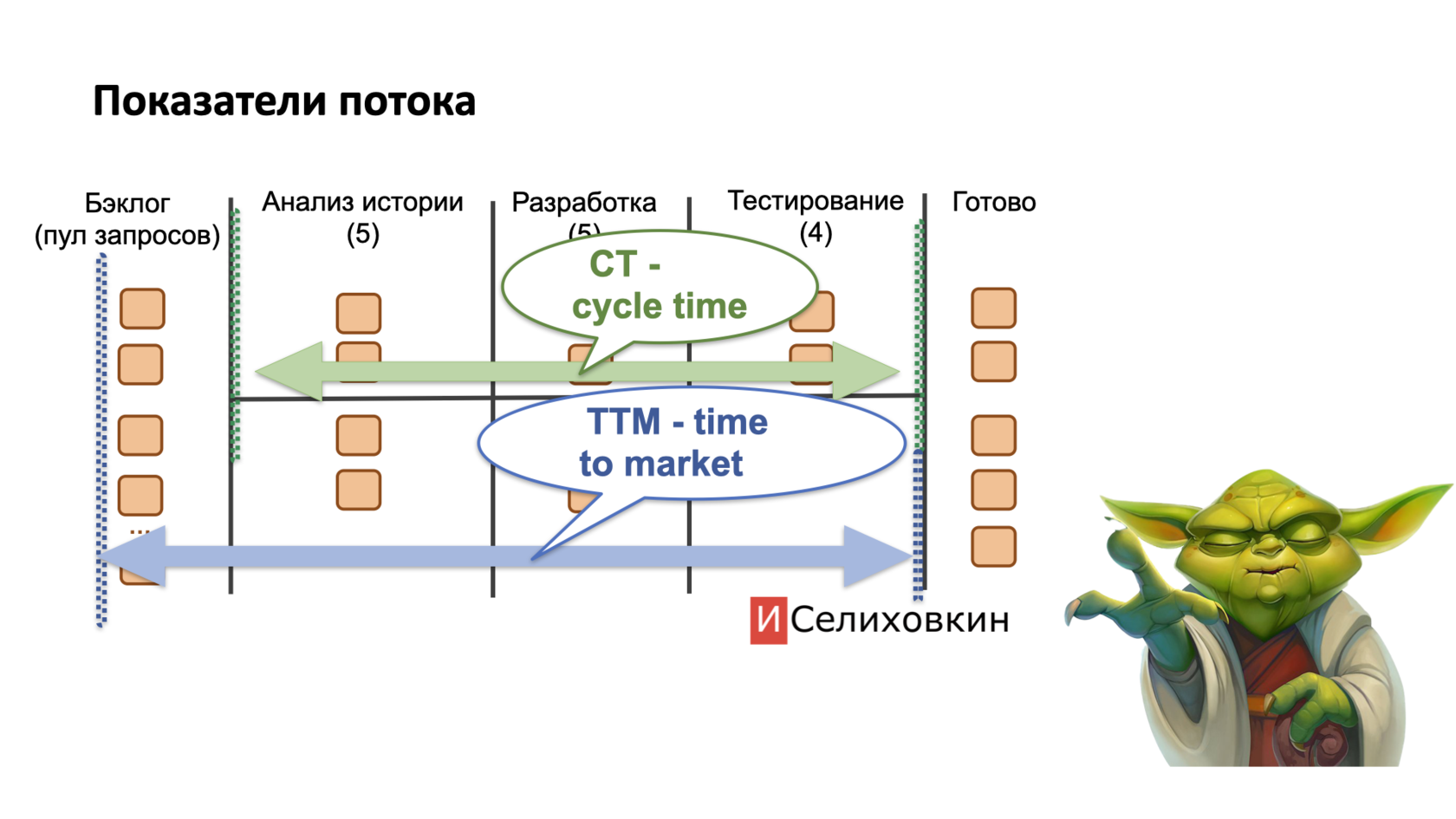
Тут стоит подчеркнуть, что "сокращение cycle time" само по себе никогда не является целью менеджмента. Чего мы действительно хотим - чтобы команда работала по-возможности быстро, но не без надрыва и не на пределе своих возможностей. Стремимся нащупать такой CT, при котором команда будет чувствовать себя хорошо и сможет работать, в идеале, годами. А нам не никого спасать от нервного истощения и бороться с ходом ключевых сотрудников.
Не существует никаких "стандартно-хороших" CT, все зависит от специфики команды, от их компетенций, от того, давно ли они занимаются продуктом и хорошо ли сработались (грубо говоря, от того на какой ступени "лестницы Такмана" находятся) и т.п.
Отмечу, что при расчете TTM и CT, при использовании Канбан метода "средние" величины (по команде, по компании в целом) как правило, мало о чем говорят, т.к. у разных запросов разная трудоемкость.
Эта тема которой я не буду касаться тут подробно. Отмечу, что важное упражнение, которое обязательно стоит проделать, прежде чем собирать данные - решить вместе с командой, для каких запросов мы измеряем CT.
Скажем, в продуктовой команде можно собирать несколько видов CT - для стандартных User Story от менеджера продукта, трудоемкостью не менее чем условный X и не более чем условный Y; для очень больших UserStory (больше чем Y); для срочных запросов и т.п.
Эта тема которой я не буду касаться тут подробно. Отмечу, что важное упражнение, которое обязательно стоит проделать, прежде чем собирать данные - решить вместе с командой, для каких запросов мы измеряем CT.
Скажем, в продуктовой команде можно собирать несколько видов CT - для стандартных User Story от менеджера продукта, трудоемкостью не менее чем условный X и не более чем условный Y; для очень больших UserStory (больше чем Y); для срочных запросов и т.п.
Когда упражнение завершено - можно собирать информацию. Нас волнуют и абсолютные значения (от команды к команде), и их динамика, и то, можем ли мы назвать корневую причину этих отличий.
В анализе, я, особенно на уровне компании, никогда не ориентировался только на среднее но, скорее на некий "размах".
Мой основной график для анализа TTM и CT выглядел как терминал брокера с набором так называемых "японских свечек". Видимо сказалась определенная специфика работы в финтехе несколько лет.
Мой основной график для анализа TTM и CT выглядел как терминал брокера с набором так называемых "японских свечек". Видимо сказалась определенная специфика работы в финтехе несколько лет.
"Японская свечка" тем и хороша, что по ее телу виден размах (в какие значения чаще всего мы укладывались за период), а по "усам" - выбросы (которые могут свидетельствовать об аномалии).
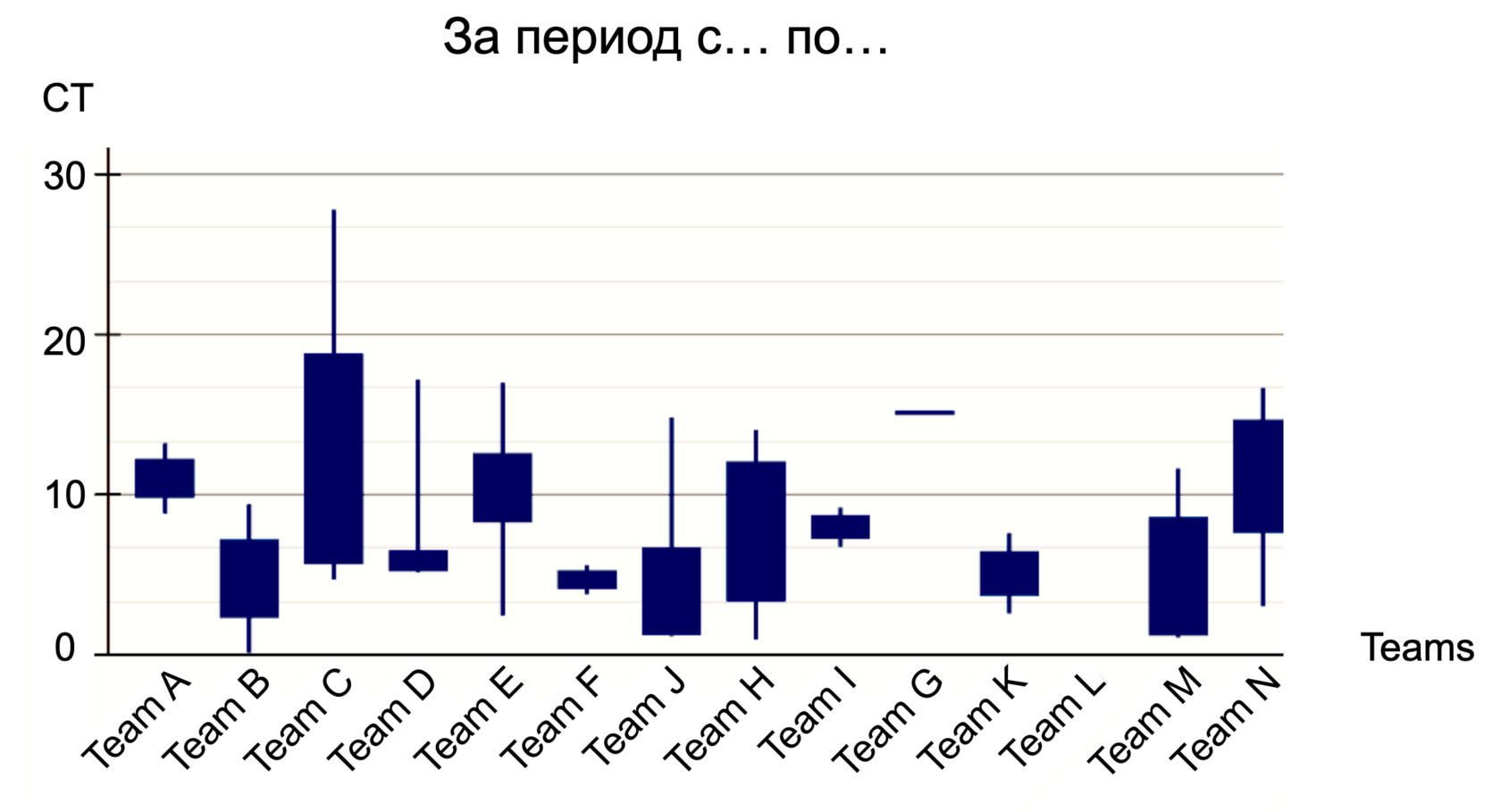
Например, какая-то команда запросы из бэклога средней для себя трудоемкости обычно реализует за 10-12 дней, но был один запрос, который занял аж 65 (начался еще в позапрошлом анализируемом периоде и мы только-только закончили). Этот выброс видно на "усе". Менеджеру стоит обратить внимание - проанализировать корневые причины, понять разовая ли была девиация (если так - то можем ли мы быть уверены что она не повторится) или есть системная проблема (каковы ее корневые причины, можно ли устранить).
Причем работу мы организовывали так, чтобы менеджеры, в первую очередь, сами, по вверенным командам, анализировали эти показатели, проводили ретро, разбирались. Я же, как хед ПМов отслеживал такую статистику с запозданием (каждый месяц), когда команда уже приложила усилия чтобы все решить, либо наоборот, уперлась в непреодолимый барьер и менеджер уже подключил меня в помощь.
Словом, анализ свечей по TTM и CT, это лишь "дабл чек" - понимаем ли мы что появилась тенденция к замедлению, что был какой-то экзотический инцидент - не упустили ли это, что сделали. Возведенный в привычку, этот анализ поможет не пропустить крупных проблем ни менеджеру, ни хедам.
Словом, анализ свечей по TTM и CT, это лишь "дабл чек" - понимаем ли мы что появилась тенденция к замедлению, что был какой-то экзотический инцидент - не упустили ли это, что сделали. Возведенный в привычку, этот анализ поможет не пропустить крупных проблем ни менеджеру, ни хедам.
Подводя итог, отметим - в ситуации, когда TTM очень высокий, а CT низкий (частая история) - следует предположить, что команда "перформит" прекрасно, но у них просто слишком большая очередь в бэклоге. Руки просто не доходят до всех запросов.
Это тоже симптом, разбираться с ним надо с вовлечением менеджера продукта (потенциальные решения - привести подмогу или распределить задачи на другие команды и/или несколько иначе наполнять и приоритезировать бэклог).
Это тоже симптом, разбираться с ним надо с вовлечением менеджера продукта (потенциальные решения - привести подмогу или распределить задачи на другие команды и/или несколько иначе наполнять и приоритезировать бэклог).
Flow efficiency (FE) - эффективность потока
Flow efficiency - позволяет понять, сколько % времени запрос “мариновался” без участия специалистов, с того момента, как был взят в работу (например, лежал на согласовании или ожидал приемки).
Чаще всего FE измеряется на том же отрезке, что CT, хоть это и не обязательно.

Поясним на примере.
У нас в работе некий запрос, который движется по цепочке - уточнение у аналитика, разработка, тестирование, "готово". Такой донельзя упрощенный flow.
У нас в работе некий запрос, который движется по цепочке - уточнение у аналитика, разработка, тестирование, "готово". Такой донельзя упрощенный flow.
Аналитик первый взял запрос в работу, уточнил, до-описал и передал программистам. Но разработчики еще три дня не обращали на запрос внимания, были заняты чем-то другим.
Потом, наконец, взялись и сделали, отдали на тестирование. Но тестировщик тоже почти два дня не подходил к запросу - завершал предыдущие дела. Потом проверил и сразу же залил на "прод".
Потом, наконец, взялись и сделали, отдали на тестирование. Но тестировщик тоже почти два дня не подходил к запросу - завершал предыдущие дела. Потом проверил и сразу же залил на "прод".
Таким образом, с того момента, как работы над запросом / задачей начались - он суммарно провисел в статусах, "ожидая" что на нее обратят внимание суммарно 5 дней. Три из них он ждал разработчиков и еще два ожидал тестировщиков.
Допустим, что CT для данного запроса был 12 дней. Получается 5 из 12 запрос "мариновался" в ожидании, и 7 из 12 кто-то над ним работал.
Эффективность нашего потока для этого запроса = 7/12 = 0,58, т.е. 58%
Другими словами можно сказать: мы суммировали время в рабочих статусах и сравнили его c CT.
Интуитивно кажется, что чем ближе FE к 1, тем меньше простоев и тем лучше. Но все не так просто :)
Интуитивно кажется, что чем ближе FE к 1, тем меньше простоев и тем лучше. Но все не так просто :)
Flow Efficiency равный 100% означал бы, что как только задачу сделет разработчик ее мгновенно хватает тестировщик и так далее по цепочке). На практике, такое приемлемо лишь для супер-срочных запросов (ради которых откладывают все остальное). В остальных случаях стопроцентный FE сигнализирует, что наша команда недозагружена. Потому всегда есть пара рук, готовых приняться за работу. Так что стремиться к 100% показателям не стоит.
Единых норм Flow Efficiency не существует, для каждой команды нащупываем свой оптимум а потом следим за аномальными колебаниями.
Throughput - пропускная способность
Throughput- пропускная способность - сколько команда "переварила" за период.
В Скраме практически аналогом Throughput выступает velocity. В Канбан и классическом проектном управлении показатель стоит рассчитать отдельно.
Суть такова: все задачи в нашем бэклоге имеют какую-то трудоемкость (не важно в чем она оценена - в стори-поинтах, в "майках", человеко-часах или еще каких-то условных единицах). Мы выбираем определенный период и смотрим, какова суммарная трудоемкость взятых в разработку и успешно завершенных запросов.

Стоит заранее определиться, как именно ведем подсчет.
На практике обычно возникают вопросы из серии "а что если у нас один из старых запросов большой трудоемкости был три месяца в разработке и только-что завершился - его куда считать, в какой период?".
Не буду углубляться, но чтобы показатель был максимально информативным - анализируемый период должен коррелировать с CT большинства запросов. Условно, нет смысла измерять throughput каждую неделю если у вас практически не бывает User Story которые можно реализовать быстрее чем за месяц.
На практике обычно возникают вопросы из серии "а что если у нас один из старых запросов большой трудоемкости был три месяца в разработке и только-что завершился - его куда считать, в какой период?".
Не буду углубляться, но чтобы показатель был максимально информативным - анализируемый период должен коррелировать с CT большинства запросов. Условно, нет смысла измерять throughput каждую неделю если у вас практически не бывает User Story которые можно реализовать быстрее чем за месяц.
Отмечу также, что при помощи throughput я обычно измеряю именно пропускную способность "создавать что-то новое" (то, чего раньше не было в продукте, что имеет ценность и двигает его вперед).
Практически любой бэклог помимо "новых фич" (User Story etc) содержит запросы на устранение технического долга, некритичные баги. Их мы в подсчетах throughput не учитываем. Таким образом, показатель становится более логичным и легко читаемым.
Допустим, в прошлых месяцах throughput команды был в районе 30 условных единиц. А в этом резко упал до 15. Что случилось?
Если другие показатели, такие как CT не просели, то первое же предположение - команда переключилась на "правку багов"/"закрытие старых технических долгов".
Ни секунды не сомневаемся, что залатывание дыр, это важное занятие, но все же очень полезно подчеркивать во всех отчетах - чем больше мы этим занимаемся, тем меньше нового идет на прод. На поздних стадиях существования продукта это вполне нормальная ситуация. Но если throughput резко падает на ранних стадиях или при выводе MVP - стоит задуматься и перепроверить себя.
Если другие показатели, такие как CT не просели, то первое же предположение - команда переключилась на "правку багов"/"закрытие старых технических долгов".
Ни секунды не сомневаемся, что залатывание дыр, это важное занятие, но все же очень полезно подчеркивать во всех отчетах - чем больше мы этим занимаемся, тем меньше нового идет на прод. На поздних стадиях существования продукта это вполне нормальная ситуация. Но если throughput резко падает на ранних стадиях или при выводе MVP - стоит задуматься и перепроверить себя.
Знаете шутку про "слово которое запрещено произносить при CEO - рефакторинг"? Так вот слово-то не запрещено, но и цену его стоит визуализировать в привычных повседневных показателях. Один из них - throughput.
Поставка ценности
Здесь мы практически "двумя ногами" заходим на территорию продакт-менеджмента. Но, отметить стоит. Если менеджер продукта не просто приоритезирует запросы которые размещает в бэклоге, но назначает им условные единицы ценности, то можем считать сколько ценности мы поставили пользователю в единицу времени.
Фактически мы измеряем throughput. в единицах ценности.
Т.е. в наших руках оказывается супер-метрика, понятная не только производственникам, но и продакт менеджерам, и бизнесу.
Т.е. в наших руках оказывается супер-метрика, понятная не только производственникам, но и продакт менеджерам, и бизнесу.
Иногда, совместно с CPO нам удавалось настроить и запустить простые правила оценки ценности - единые на всю компанию. И договаривались, что и одна user story не идет в работу пока ее ценность не оценена. В итоге удавалась выстроить и отслеживать простую связь - все наши производственные метрики CT, TTM, FE, пропорция багов и техдолга в каждом периоде - коррелирует с ценностью мы дотащили или не дотащили до пользователя вчера-позавчера-за прошлые три месяца и т.п.
Отклонение от вех
Отклонение от вех в днях и % - показывает насколько хорошо мы умеем укладываться в собственные прогнозы.
Совершенно нетипичная для Канбан метода метрика. Ее можно было бы легко представить в классическом проектном управлении (где уместно смотрится и сам термин "веха"). И уж тем более сложно это представить в Скрам.
Основная идея анализа этой метрики - тренировка команды в выработке реалистичных оценок
В продуктовых компаниях далеко не все запросы имеют обоснованный дедлайн. Но у некоторых он есть. Будь то значимая фича которую "кровь из носа" нужно выпустить к рождественской распродаже. Или изменения в платежном модуле без которых через месяц весь наш софт окажется вне закона. Или просто функциональность, которую от нашей команды ждут три других и спрашивают "ну когда, сориентируйте пожалуйста, чтобы мы могли свою работу подстроить".
Так вот, дедлайны нужны лишь в некоторых случаях. Но без регулярной тренировки, на многих запросах, те самые критичные с большой вероятностью будут провалены.
В продуктовых компаниях далеко не все запросы имеют обоснованный дедлайн. Но у некоторых он есть. Будь то значимая фича которую "кровь из носа" нужно выпустить к рождественской распродаже. Или изменения в платежном модуле без которых через месяц весь наш софт окажется вне закона. Или просто функциональность, которую от нашей команды ждут три других и спрашивают "ну когда, сориентируйте пожалуйста, чтобы мы могли свою работу подстроить".
Так вот, дедлайны нужны лишь в некоторых случаях. Но без регулярной тренировки, на многих запросах, те самые критичные с большой вероятностью будут провалены.

Мы должны практиковаться прогнозировать срок своей работы и анализировать "сбылось или нет", выявлять причины промашек, накапливать опыт, который пригодится нам в нужный момент.
Обычно мы делаем это так.
Метрику "отклонение от вех" собираем, как минимум, для тех же запросов, для каких считаем throughput. Т.е. для достаточно значимых (не слишком мелких) и таких которые приносят понятную пользу заказчику..
Метрику "отклонение от вех" собираем, как минимум, для тех же запросов, для каких считаем throughput. Т.е. для достаточно значимых (не слишком мелких) и таких которые приносят понятную пользу заказчику..
Представьте - при разработке крупной или средней User Story. На своем пути она сменяет несколько статусов. Иногда их бывает довольно много (например, "аналитика", "дизайн", "разработка", "Quality Assurance", "сборка и публикация" и им подобные).
По имеющимся у нас данных самые долгих и, безусловно самых дорогих стадии всего две - это "разработка" и "QA". Т.е. если научимся предсказывать их продолжительность, то и в целом сможем сориентировать коллег "когда ждать фичу".
По имеющимся у нас данных самые долгих и, безусловно самых дорогих стадии всего две - это "разработка" и "QA". Т.е. если научимся предсказывать их продолжительность, то и в целом сможем сориентировать коллег "когда ждать фичу".
Заводим простое правило - чтобы передвинуть задачу статусы "разработка" и в "QA" - нужно задать плановые даты завершение каждого из них. Это единственное, что нужно сделать вручную. Остальное, хороший таск-трекер или система управления проектами выполнит сама. Например, в Jira мы реализовывали это через кастомные поля, которых нужно 2 штуки на каждый статус "дата планового завершения" и "дата фактического завершения". Первое система будет проставлять автоматически, когда запрос переходит в статус или покидает его. Второй как раз нужно будет проставить менеджеру вручную, посоветовавшись с командой. Также нам пригодится информация "сколько времени запрос провел суммарно в данном статусе".
Затем мы будем анализировать, насколько разошлись плановая и фактическая дата завершения (в днях и в %). Нам всегда будут важны оба значения по каждому из статусов.
Так, спустя 2-3 временных периода мы сможем отметить, например:
"В нашей команде мы в среднем на 20-30% (5-7 дней) промахиваемся с оценкой разработки.
И практически не ошибаемся с QA - отклонения на 0-10% (0-1 день)."
Получается, процесс QA в нашем примере высоко предсказуем. А разработчики в собственные оценки попадать пока не умеют. 30% возможно не кажется большим отклонением для ИТ-мира, но в рамках отдельно взятой User Story это серьезный перекос, стоит попробовать улучшить точность со временем.
Затем мы будем анализировать, насколько разошлись плановая и фактическая дата завершения (в днях и в %). Нам всегда будут важны оба значения по каждому из статусов.
Так, спустя 2-3 временных периода мы сможем отметить, например:
"В нашей команде мы в среднем на 20-30% (5-7 дней) промахиваемся с оценкой разработки.
И практически не ошибаемся с QA - отклонения на 0-10% (0-1 день)."
Получается, процесс QA в нашем примере высоко предсказуем. А разработчики в собственные оценки попадать пока не умеют. 30% возможно не кажется большим отклонением для ИТ-мира, но в рамках отдельно взятой User Story это серьезный перекос, стоит попробовать улучшить точность со временем.
Подсчитывая отклонения от вех, очень важно "не пережестить". Не создать ощущения у команды, что в каждую такую оценку нужно попадать "кровь из носа" (как мы писали выше - это не так), Подчеркиваем, что для большинства запросов вехи - лишь тренировка навыка оценивания. Стараемся вызвать спортивный интерес (давать реальные оценки), но не провоцировать команду на ненужные переработки или на раздувание оценок ("чтобы точно уложиться").
Действительно важные дедлайны обозначаем отдельно - цветом или ярким тегом или иным способом каким позволяет наша система (Jira, например, позволяет любой из перечисленных).
Вспомогательные метрики работы

Перечисленного выше хватает для общих выводов об эффективности работы, пожалуй, большинства ИТ-команд. Их или аналоги я рекомендую собирать всегда. На них можно и нужно обращать внимание всех команд, хедов, лидов, топ-менеджмента на митах, посвященных обсуждению эффективности.
Однако, для целостной картины может потребоваться множество вспомогательных показателей. Перечислю их списком с минимальными пояснениями.
- Пожарные метрики "Аа-а-а-а-а! Срочно!" - связанные с реализацией срочных запросов, например. TTM, CT, для самых срочных запросов - должно быть минимальным, а время первой реакции (от поступления в бэклог до появления первых конструктивных комментариев или перевода в следующий статус) - должно укладываться в некий заранее установленный норматив. Например, "время реакции на критичные инциденты от техподдержки не должно превышать 1 час)
- Время, проведенное запросом в каждом из статусов (не требует регулярного анализа, но будет полезным при при поиске корневых причин когда "расползется" любая другая метрика, например TTM или CT)
- Пропорции (сколько сделано или запланировано сделать новой функциональности и сколько поправлено багов, ликвидировано технического долга и т.п.). Измеряем обычно и в "штуках" и в суммарной трудоемкости. Хорошо дополняет при анализе изменения throughput.
Группа II. Метрики комфорта
Кроме чисто производственных показателей (TTM, CT, FE и другие перечисленные выше) важно уметь замерять самочувствие и отношение людей в команде и вне ее. Как мы уже говорили, ИТ-бизнес состоит из людей, их воли, желания, мотивированности, психологического комфорта.
Абсолютно минимальный набор, на мой взгляд, состоит из двух метрик: "NPS" и "текучка" + непрерывная работа хеда менеджеров со своей менеджерской командой.
Net Promoter Scope (NPS) - популярная метрика для измерения отношения.
Суть метрики одним абзацем: вы просите оценить продукт или услугу у того, кто ей пользовался по шкале от 0 до 10. Причем вопрос формулируется так "посоветуете ли вы этот продукт / услугу своему лучшему другу, если ему это будет актуально?". 10 - безусловно да, 0 - ни в коем случае не посоветую.
Суть метрики одним абзацем: вы просите оценить продукт или услугу у того, кто ей пользовался по шкале от 0 до 10. Причем вопрос формулируется так "посоветуете ли вы этот продукт / услугу своему лучшему другу, если ему это будет актуально?". 10 - безусловно да, 0 - ни в коем случае не посоветую.
При анализе ответов считаем, что 0-6 это негативный результат (от работы с вами или с вашим продуктом будут отговаривать). 7-8 результат нейтральный (годится, но восторга не вызывает). 9 и 10 - это идеальный результат, у вас получается очень хорошо, вас, скорее всего, без вашего ведома уже вовсю настойчиво советуют друг другу.
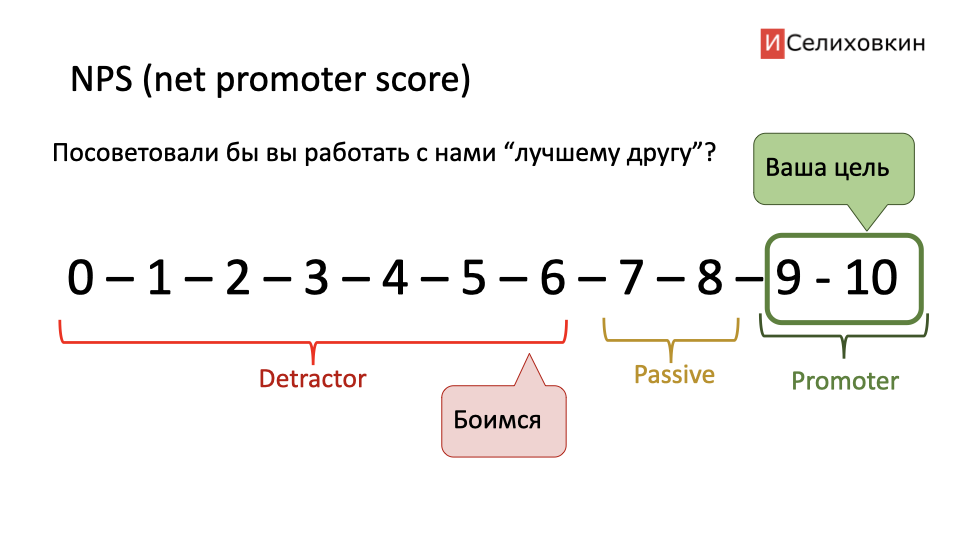
Я использую NPS как простой и лаконичный способ узнать как коллегам работается со мной в команде (сам опрос порой можно и нужно делать анонимным). Проверяю как относятся к моим менеджерам. А, также замеряю, довольны ли нами смежные департаменты (например юристы, финансисты, топ-менеджеры и все остальные с кем мои сотрудники соприкасаются).
Важная особенность NPS - его нельзя собирать слишком часто. Предельно возможная частота 1 раз в квартал (лучше 1 раз в пол года - но нужно смотреть по ситуации). В противном случае у коллег "замыливается глаз" и они воспринимают такой опрос как рутину, ставят одни и те же цифры не задумываясь.
Я обычно все же предлагаю, при желании, прокомментировать оценку, иногда дополняю опрос еще парой уточняющих вопросов. Но NPS - главное "ядро".
Резкое проседание NPS внутри команды может говорить, что люди устали, выгорели, демотивированы, не готовы работать с вами так, как делали это раньше. Снижение NPS в отношении конкретных менеджеров или всей управленческой команды - может говорить об обманутых ожиданиях, разочаровании. В целом, для меня, это всегда сигнал плохой работы с ожиданиями стейкхолдеров
NPS, потенциально - так называемый "опережающий показатель". С его помощью вы можете заметить перепады в отношении до того как они выльются в реальные проблемы
Текучка - количество и удельный вес увольнений в команде за определенный период.
В отличие от NPS, текучка - классический "запаздывающий показатель". Это свершившийся факт.
NPS говорит об эмоции, отношении, наводит на мысль "что может случиться". Текучка показывает "что в итоге случилось".
NPS говорит об эмоции, отношении, наводит на мысль "что может случиться". Текучка показывает "что в итоге случилось".
Определенный уровень текучки неизбежен в любой компании. Но, резкие ее подъемы без явных причин, могут говорить. например, о менеджерских ошибках. Так, иногда, затеянные нами трансформации могут не только не приводить к росту запланированных метрик, но и вызывать сильное разочарование и даже отток сотрудников.
Так что текучка - важный, я бы сказал "контрольный показатель" нашей адекватности.

И другие. Разумеется, метрики комфорта разнообразны и вы можете дополнять список своими любимыми. Я умышленно привел тут лишь минимальный джентльменский набор, который сам неизменно мониторю во всех компаниях.
Группа III. Метрики бизнеса и компании
Продуктовой компании - продуктовые метрики.
Разработка их - в целом вотчина CPO (Chief Product Owner вместе с другими продуктовыми менеджерами). При этом, свободно читать продуктовые метрики должны все, без исключения, сотрудники и уж тем более, менеджеры любого ранга.
Перечислим самые главные из них простым списком:
- MAU - количество активных пользователей в месяц
- DAU - количество активных пользователей в день
- retention (N-day retention) - какой % пользователей возвращается к использованию продукта к дню N
- LTV - сколько пользователь приложения принесет за время его использования
- Churn rate - % "отвала" пользователей, в некотором смысле обратное retention
- Revenue - доход
- ARPU - средний доход с каждого пользователя.
Также, если помните, выше мы уже упоминали оценку пользовательской ценности (которую впоследствии удобно сочетать с throughput).
Если метрики работы полезно анализировать совместно с менеджерами и упоминать на митах посвященных повышению эффективности; метрики комфорта стоит держать приватными не афишируя без нужды; то продуктовые метрики в продуктовых компаниях обычно распространяют максимально широко.
Хорошая идея - сделать их настолько общедоступными, насколько это возможно - использовать информационные радиаторы, такие, как корпоративный портал или монитор с графиками и трендами, висящий у входа. Это помогает вовлечь команды в разработку продукта, а также усиливает ощущения общего дела. И иногда помогает визуализировать без того трудно ощутимые результаты.
Вот мы пилим-пилим, эффективность повышаем. А ради чего? Хоть кому-то от этого хорошо стало? Наш продукт вообще кому-то нужен?
Да, смотрите, нужен. Графики растут. Или не растут - тут уж как пойдет. Но я абсолютно уверен что каждому человеку в компании полезно знать реальное положение дел. Сознавать, насколько успешно или провально его (в том числе) детище.
Да, смотрите, нужен. Графики растут. Или не растут - тут уж как пойдет. Но я абсолютно уверен что каждому человеку в компании полезно знать реальное положение дел. Сознавать, насколько успешно или провально его (в том числе) детище.
В еще большей степени этот эффект призваны усилить единые цели, поставленные компанией на какой-то отрезок времени (OKR, KPI, North Star / North Pole metric) и декомпозированные по командам. Стремление к достижению показателей заостряет чувство, условно, что "я не просто ношу камни, но строю храм". Однако, в данной статье я намеренно не стану раскрывать эту тему. Разговор о целеполагании, плюсах и минусах, декомпозции, жестких ли (как KPI) или мягких и вовлекающих (как OKR) подходах требует ни одного десятка абзацев и множества примеров. Отметим лишь что подходы к целеполаганию могут и должны разумно сочетаться с темб как вы планируете развитие продукта и как измеряете собственную эффективность.
Подойдут ли метрики вне Канбана?
Почему нет? Вопросы могут быть только с метриками работы. Но сомнения легко рассеять.
Само собой, в классическом проектном подходе важнейшими показателями будут также "попадание проекта в тройственные ограничения", и достижение целей обозначенных в уставе. Но в этой статье я не буду переключаться на отличия каждого из подходов и каждого вида компаний (тут мы рассматриваем продуктовую специфику). Перечислим лишь сравнительно универсальные показатели.
Суть TTM и CT - померить, "сколько ждет заказчик с того момента, как... (положил в бэклог / первый член команды прикоснулся к запросу)". Можем это измерить внутри Скрам фреймворка? Без проблем. Да, мы работаем по спринтам (вероятно, показатели будут меняться скачками - в зависимости от того, в каком спринте запрос доедет). Но метрику-то мы получим, как и ответ "сколько ждал...".
В классическом проектном подходе существует понятие "трассировки требований", в его состав может входить и анализ "сколько времени прошло от момента возникновения / добавления в матрицу требований до подтверждения от стейкхолдера". Никаких проблем не возникает.
В классическом проектном подходе существует понятие "трассировки требований", в его состав может входить и анализ "сколько времени прошло от момента возникновения / добавления в матрицу требований до подтверждения от стейкхолдера". Никаких проблем не возникает.

Throughput (пропускная способность за период) в любом подходе измеряется элементарно.
Flow efficiency в классическом Скраме обычно не измеряют (уважая право команд на самоорганизацию). Но добыть приблизительные данные "из спринта" не проблема, учитывая что обычно команды применяют самый простой вариант канбан-доски (ToDO, In Progress, Done - время проведенное в In Progress и есть числитель для Throughput, со знаменателем, думаю все понятно). В классическом проектном управлении для анализа "сделанного за период", существует множество приемов, в том числе годятся некоторые показатели из метода освоенного объема (EVA).
Flow efficiency в классическом Скраме обычно не измеряют (уважая право команд на самоорганизацию). Но добыть приблизительные данные "из спринта" не проблема, учитывая что обычно команды применяют самый простой вариант канбан-доски (ToDO, In Progress, Done - время проведенное в In Progress и есть числитель для Throughput, со знаменателем, думаю все понятно). В классическом проектном управлении для анализа "сделанного за период", существует множество приемов, в том числе годятся некоторые показатели из метода освоенного объема (EVA).
Поставку ценности, отклонение от вех и прочие метрики работы разбирать не буду - для большинства из них можно подобрать метод измерения.
Ну, а метрики бизнеса и продукта, и метрики комфорта - от подхода совершенно не зависят.
Итого
Эффективность в ИТ-компаниях это способность достаточно быстро (но не в режиме героизма, без надрыва и переработок) поставлять ценность пользователям.
Измерять эффективность стоит не на уровне субъективных ощущений, а в цифрах и по заранее определенной вами методике.
Я предлагаю ориентироваться, как минимум, на три группы метрик:
- Метрики работы (TTM, CT, FE, Throughput, milestone deviation, etc)
- Метрики комфорта (NPS, текучка)
- Метрики продукта (MAU, DAU, retention, chun, LTV, ARPU)
В работе с метриками важно "не пережестить" (команда должна понимать что вы собираете их не для того, чтобы "наказать невиновных и наградить непричастных", но чтобы выявить зоны роста, анализировать корневые причины проблем и постепенно улучшить показатели). В противном случае вместо роста эффективности вы получите множество недовольных ИТ-шников, азартно пытающихся "хакнуть" ваши метрики.
Так, например, решения о премировании никогда не должны основываться только и исключительно на метриках (хотя, как дополнительный источник информации они вполне годятся)
Соблюдая же все меры предосторожности, разъясняя команде и всем окружающим "кто, кого, и зачем тут измеряет" можно и нужно получить надежный инструмент анализа "что с нашей эффективностью". И если растущий рынок дает шансы всем его участникам, то во время стагнации и снижения, когда требуется перестраиваться и приспосабливаться - реальные шансы есть лишь у немногих, действительно эффективных.
Иван Селиховкин: https://www.linkedin.com/in/selikhovkin/ и телеграм-канал: https://t.me/selihovkin


